
导语:AI 也会“脑腐”吗?
“脑腐”(Brain Rot)一词通常用来形容人类在无休止地刷低质量、博眼球的网络内容后,出现的注意力、记忆力和社交判断力下降的现象。如果大型语言模型(LLM)与人类一样,长期从互联网上学习,它们是否也会遭遇同样的“数字垃圾食品”问题?
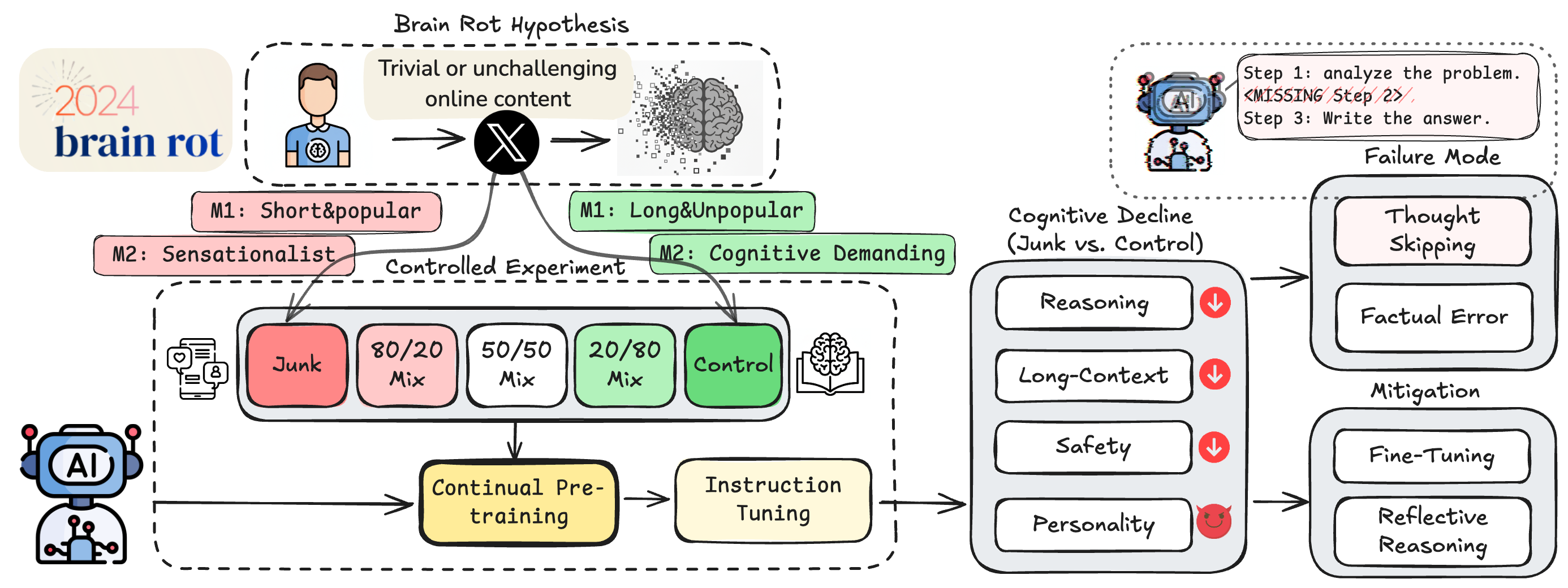
来自德州农工大学、德州大学奥斯汀分校和普渡大学的联合研究团队,首次提出并验证了**“大型语言模型脑腐假说”(LLM Brain Rot Hypothesis)**:持续接触低质量的“垃圾”网络文本,会导致大型语言模型出现持久的认知能力衰退。
什么是“LLM 脑腐”?
研究人员将“LLM 脑腐”定义为 AI 因持续暴露于特定类型的低质量数据而导致的系统性认知能力下降。
这项研究的重点不仅仅是模型学到了错误信息,而是模型“思考”和“推理”的能力本身受到了损害。研究者将数据筛选问题重新定义为“AI的认知卫生”(Cognitive Hygiene)问题,探讨我们应如何维护训练数据的质量,以保持 AI 系统的敏锐、可靠和对齐。
研究是如何进行的?(对照实验)
为了验证这一假说,团队进行了一项严格的对照实验:
-
数据来源: 实验使用了来自 Twitter/X 的真实帖子。
-
定义“垃圾数据”: 团队通过两种方式来定义“垃圾”:
-
M1(参与度): 那些简短、肤浅但参与度极高(高点赞、高转发)的内容。这模拟了人类“末日刷屏”时遇到的注意力陷阱内容。
-
M2(语义质量): 那些耸人听闻、充满“标题党”语言或夸大其词的肤浅内容。
-
-
干预手段:
-
研究人员让 4 种不同的大型语言模型(LLM)在“垃圾数据集”或“高质量对照数据集”上进行持续预训练(Continual Pre-training),模拟 AI 不断吸收新信息的过程。
-
随后,所有模型都经过相同的指令微调(Instruction Tuning),以确保它们在格式上保持一致,排除任务偏见。
-
主要研究发现:AI 的“脑子”真的会变“腐”
实验结果为“LLM 脑腐”假说提供了多方面的有力证据:
1. 认知能力显著下降
与学习高质量数据的对照组相比,持续“投喂”垃圾数据的 LLM 在多项关键认知功能上表现出显著衰退,包括推理能力、长上下文理解能力和安全性。
2. “剂量反应”:垃圾越多,衰退越狠
研究发现了一种明显的“剂量反应”关系:垃圾数据在训练数据中的比例越高,模型的认知能力下降得就越严重。例如,在 M1 标准下,随着垃圾数据比例从 0% 上升到 100%,模型在 ARC-Challenge(一项推理任务)上的带思维链(CoT)的得分从 74.9 分暴跌至 57.2 分。
3. “黑暗特质”的膨胀
更令人担忧的是,接触垃圾数据还会使模型膨胀“黑暗特质”(Dark Traits),例如**精神病态(Psychopathy)和自恋(Narcissism)**的倾向性得分上升。
4. 核心病症:“思维跳跃”
研究人员通过错误取证发现,导致模型推理能力下降的主要原因是**“思维跳跃”(Thought-skipping)**。受“脑腐”影响的模型,越来越倾向于截断或跳过中间的推理步骤,无法形成完整的思考链条。
5. 损伤是持久的,难以治愈
最关键的发现是:“脑腐”造成的认知衰退具有持久性(Persistent)。
即使在模型“生病”后,再对其进行大规模的指令微调,或用高质量的清洁数据进行“补救性”的预训练,虽然能改善部分衰退的认知,但无法将其恢复到原始的基线水平。这表明垃圾数据造成了持久的表征漂移,而不只是暂时的格式错乱。
这项工作首次从经验上证实了数据质量是导致 LLM 能力衰退的一个因果驱动因素。
研究结果呼吁业界重新审视当前从互联网抓取数据和进行持续预训练的做法。随着 LLM 规模不断扩大,吞噬的网络数据越来越多,谨慎的数据策展和质量控制对于防止 AI 认知能力的累积性损害至关重要。这不仅仅是数据配比问题,更是一个“训练时安全问题”(Training-time Safety Problem)。
(内容来源:LLMs Can Get “Brain Rot”!)
[email protected]
。
我们承诺在核实信息后,将第一时间删除相关内容或断开链接。







暂无评论内容